BHW Group Blog
Unified Search for Business Data from Multiple Sources
Submitted by Jason Gray on Monday, 11/25/13
Background
One of our clients provides an information-rich website for their customers, containing business data from multiple sources. Like all companies, our client wants to make their content easily accessible for their website users; however, without a unified search for business data strategy our client could only provide search for a small portion of their data. Our client’s business data is comprised of static HTML that changes infrequently, reported financial data that changes quarterly, and real-time business data concerning real-estate holdings. This particular client happens to be a publicly traded company who is also subject to regulatory and reporting requirements concerning their quarterly reports and supporting documents. They wanted these quarterly reports to be available for search as well. As unstructured data, these reports lacked a database or other means of providing a search. Viewed as a whole, the site has numerous pages of edited copy with great detail about the company’s expertise, financials, investments, holdings, etc. There are numerous electronic documents (primarily PDF and Excel quarterly reports) available for download from the site, but not stored in a database. There is also a database that stores data on real estate properties.
Today there are many CMS options that can address the search challenges we have presented. Our client built their custom CMS system years ago and has invested a significant amount of time, energy, and money maintaining the system as well as training their users. It was important for BHW to provide our client with an option to extend their current system and leverage their investment while addressing these search challenges. Our client decided to extend their current system rather than adopt a new CMS, build new integrations to their back-end systems, and retrain their users.
The client requested a search mechanism that could handle:
- The static “infrequently changing” html content.
- The quarterly changing documents and spreadsheets of data.
- The constantly changing data on properties managed through the CMS.
The client could easily identify the data that was valuable to include in searching, but they did not have the infrastructure to manage that data in a single place or to push it to one place (database) for storage. The “website” was the system of record for the valuable data.
The Problem – Our data comes from multiple sources
We’ve defined the data we would like to search, but the data is not stored in a consistent place or format. Focusing on any one of the data sources will leave out huge chunks of valuable data from the others. We need a way to categorize the data for search so we can point each search result to the correct data source. Pointing back to the data source allows matching search results to direct the user to a document, a static web page or a dynamic web page with database content. We also need a way to keep this search index updated frequently while and not affecting website traffic. The website is hosted on a Windows Network Load Balanced (NLB) pair of servers, so we also need our solution to support a web cluster, be redundant, and provide high-availability and scaling options.
The Solution – Lucene.NET
We created a solution using Lucene.NET that would allow us to create a search index on:
- All web pages in the website directory (with or without dynamic content embedded).
- We needed the ability to filter out specific pages that were “template” pages with dynamic data from SQL server tables.
- Focus only on the true “content” of each page and not any of the repeated navigational elements, page titles, meta tags, etc…
- All electronic documents (PDF and XLSX) that could be added to each web page through the CMS.
- Specific data from tables in the SQL Server 2008 database.
The Lucene.Net index is generated by a stand-alone scheduled task. The indexer updates the search index every day in the early morning and system admins can force an update of the index at any time. The current search index is not affected by the creation of the new index. The indexer creates new index files within the main website root directory.
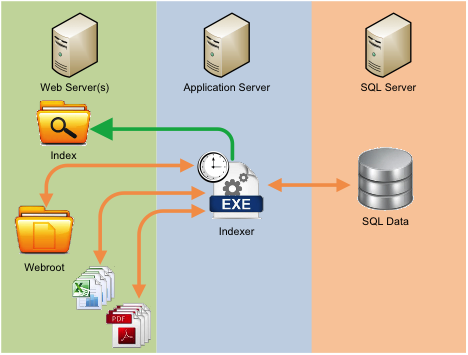
A process to index business data from multiple sources using Lucene.
The indexer code
- Lucene.Net
- iTextSharp for PDF parsing
using Lucene.Net.Analysis;
using Lucene.Net.Analysis.Standard;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.Store;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
using Directory = Lucene.Net.Store.Directory;
using Version = Lucene.Net.Util.Version;
Index steps (high level):
- Index the web pages
string[] directories = System.IO.Directory.GetDirectories(ConfigurationManager.AppSettings["Webroot"]);
foreach (string directory in directories)
{
string[] files = System.IO.Directory.GetFiles(directory);
foreach (string file in files)
{
//We read the content of the page as it would be served from the web server.
//open file
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(ConfigurationManager.AppSettings["WebsiteUrl"] + "/" + directory + "/" + file);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
//We did various regular expression parsing and read only specific parts of the web page HTML that were considered “CONTENT”. We also set specific formatting based on which section of the website we were in so that the search result was formatted to look like it belonged to a part of the website.
//Then we added a “Document” to the Lucene index that contained the formatted string of data.
}
}
- Index the database tables (of interest)
- Connect, query and convert the data into a Lucene document and add it to index.
- Index the content of the PDF and XLS files
- The pointers to our downloadable document “Assets” are stored in a database table.
- We grab those pointers and open the document(s) with iTextSharp, read the content of the document, convert it to a Lucene document and add it to the index.
- Store the index on the web server in the main webroot directory where it is easily accessible form the website search feature.
Using the Index
The ASP.Net web application has a custom search feature in the main top level menu throughout the site and an “advanced search” page that is hooked into the search index. Search results are returned to the “search results” page in a way that identifies the result as a web page, downloadable document or a dynamic property result and the search results page formats the result accordingly.
//Setup Index
string indexDirectory = ConfigurationManager.AppSettings["IndexDirectory"];
Directory directory = FSDirectory.Open(new DirectoryInfo(indexDirectory));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_29);
IndexReader indexReader = IndexReader.Open(directory, true);
Searcher indexSearch = new IndexSearcher(indexReader);
var queryParser = new QueryParser(Version.LUCENE_29, "content", analyzer);
var query = queryParser.Parse(searchBy);
TopDocs resultDocs = indexSearch.Search(query, indexReader.MaxDoc());
var hits = resultDocs.scoreDocs;
foreach (var hit in hits)
{
//I mentioned before that we do quite a bit of custom “configuration” within the search index so that each result is categorized appropriately so that we can format the result appropriately (color coding based on section of website) and point the user to the correct web page or downloadable document.
}
Additional Resources
http://www.codeproject.com/Articles/320219/Lucene-Net-ultra-fast-search-for-MVC-or-WebForms http://www.codeproject.com/Articles/29755/Introducing-Lucene-Net
Do you need an expert in web development? With a team of web development specialists covering a wide range of skill sets and backgrounds, The BHW Group is prepared to help your company make the transformations needed to remain competitive in today’s high-tech marketplace.