BHW Group Blog
MongoDB assisting SQL apps
Submitted by Jason Gray on Tuesday, 09/23/14
MongoDB in a Common Scenario
MongoDB is now the fifth most commonly used database in the world. Frequently clients approach MongoDB and NoSQL from an all or nothing position. They chose to completely adopt NoSQL or stay entirely with an RDBMS. Imagine a scenario where your company or your client’s company is heavily invested in the "Microsoft Stack" and has a mature on-line software product that has grown over many years. Maybe your software started as Classic ASP, was converted to .Net and even to MVC in recent years. The database backend is SQL Server or some other relational database management system. As the application’s features, users, and data have grown over the years, more hardware was added to keep it running smoothly. You have employed the skillsets of application and database architects over many years and they have employed all kinds of strategies to manage (offload, archive, and index) data and maximize the responsiveness of the features of your product.
What happens when you feel like you have done all that you can do to make your product the best that it can be from an application, database, and hosting perspective, but that is no longer good enough? Some of your software’s features have increasingly gotten slower. Doing nothing means that you begin to lose customers (market presence) as your application can’t keep up with competitors or the expectations of the users.
We were faced with a problem where a client’s on-line software was experiencing very slow response times and even occasional SQL timeouts on the site’s most used feature… SEARCH.
We needed a solution that could easily scale, could be easily managed by the client, and could integrate seamlessly with the existing software with little to no impact to the existing application code or database structures.
BHW investigated several options and thought that a NoSQL solution would be the perfect fit for the problem.
The Problem – Multi-faceted, structured data normalized through numerous foreign-keyed tables
The main data table being searched was already a "wide" table with 30+ [nvarchar] and [ntext] columns that all needed to be searchable by keyword. They included things like descriptions, qualifications, and instructions, to name a few. This table was also "foreign key" linked to about 15 other "primary key" tables through bridge tables (1 to many and many to many) and many of those tables were subsequently linked to other tables. Printing out a database diagram for just the relationships tied to this main table would take numerous printer pages (taped or stapled together) using a size 8 font.
The existing stored procedures responsible for performing these searches are [relatively] large and complex and they already use many optimized SQL views that trim and cache the lists of possible results. The main search stored procedure accepts 65 individual parameters and is almost 800 lines long and uses a variety of temp tables and additional optimized SQL functions.
I am guessing that you are getting a good picture of the complexity of the situation at hand and the difficulty in trying to improve performance while maintaining all of the possible search options.
The Solution – NoSQL with MongoDB
The solution didn’t come to us all at once. We understood the problem and did not have a lot of confidence that we could implement a solution within the confines of SQL server that would provide a drastic improvement in search. We knew that we needed to somehow take the "searchable" data from SQL and flatten it out into "objects" that we could serialize and store in some other way. We could then use those flattened out objects in the search process. We decided to store these objects as "documents" using MongoDB.
After we decided on Mongo, we knew that we had to design a solution that would keep our MongoDB "data store" synchronized with the SQL database. We also knew that we had to replicate all of the existing search functionality (remember the 65+ search parameters) available in the SQL stored procedures and have a new system that would perform drastically better than the existing one.
Step 1: Design the MongoDB documents
We installed MongoDB on a developer laptop and began designing the [MongoSearch] object that would hold our searchable data. Our [MongoSearch] object was based on the C# "model" classes from the MVC application. We condensed field names as much as possible to reduce the overall size of the resulting objects, and created a map to relate the MongoDB fields to the SQL data table fields for future reference. This was done intentionally to obfuscate the data as well as save storage space. The C# class looked like this:
```Serializable
public class MongoSearch: IMongoQuery
{
[BsonId]
public Guid Id { get; set; }
public int RId { get; set; }
public int CId { get; set; }
public int PCId { get; set; }
Rid, Cid, and PCId are examples of some of the foreign key fields within the main table. They are one-to-one relationships.
Bit fields (or Booleans) were represented as bool in the model:
public bool FgAb { get; set; }
public bool FgRv { get; set; }
Small (<25 characters) nvarchar fields were represented as strings:
public string ENm { get; set; }
public string Loc { get; set; }
- All of the "keywords" from all of the nvarchar and ntext fields were pushed into one "Keywords" field.
public string Keywords { get; set; }
Then we had multiple dates and decimals and float fields:
public DateTime? ElDt { get; set; }
public DateTime ExDt { get; set; }
public double MinAmt { get; set; }
All of the related data was flattened out to arrays of strings or integers and included in the object as such:
public List<int> AppLst { get; set; }
public List<string> TrvLst { get; set; }
Step 2: Load MongoDB
We then began writing code that would query all active results from the "main table" and loop through those results and query more tables or call stored procedures to fill in all related data. We then flattened out all relational data, filtered text fields, and stored the resulting [MongoSearch] object as JSON. For the large [nvarchar] and [ntext] data columns, we executed a regular expression on the text to pull out just the "searchable" keywords. The regular expression cut out many common words like "an", "and", "the", "as" and resulted in a condensed list of words used in later matching.
\W(a|about|an|and|are|as|at|be|but|by|can|do|for|from|had|have... etc. etc.
This "loader" application was essentially a tool that was used initially to populate MongoDB, but also served a dual purpose to recover from any synchronization problems (Step 3). We didn’t design this "loader" application to be exceptionally fast or fancy, but it is a pretty complex task to build out all of the possible data relations. A small subset of the resulting JSON object stored in MongoDB looked something like this:
{
"_id" : "hWqn7bSD/kStpZQ+dTZZYQ==",
"RId" : 280501,
"CId" : 165,
"PCId" : 5488,
"FgAb" : false,
"FgRv" : true,
"ENm" : "zappos.com",
"Loc" : "las vegas, nv",
"ElDt" : ISODate("2014-03-05T05:00:00Z"),
"ExDt" : ISODate("2017-12-31T05:00:00Z"),
"MinAmt" : 3.45,
"AppLst" : [16,21,23,45,47,55,98,101],
"TrvLst" : ["F4","F9","H21","K12","M13","P33","X5"],
"Keywords" : ["victorious","general","american","revolution","president","united","states","successful","planter","entrepreneur","legacy","george","washington"]
}
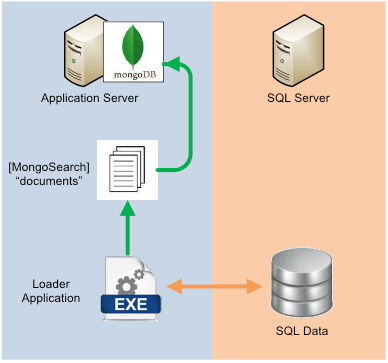
In our testing against a copy of a "representative" client database, we were able to load 290,000 [MongoSearch] JSON records into MongoDB at a total size of about 80MB.
Step 3: Synchronize SQL Server and MongoDB
One of our greatest concerns with this approach was how to keep the search data in MongoDB up to date with the data in these large SQL server clusters. We wrote SQL CLR triggers to do the job for any inserts, updates or deletes from the main table and related tables. Any modification to the "searchable" data was almost instantaneously "available" in the MongoDB document store by pushing a new "document" to replace the existing one.
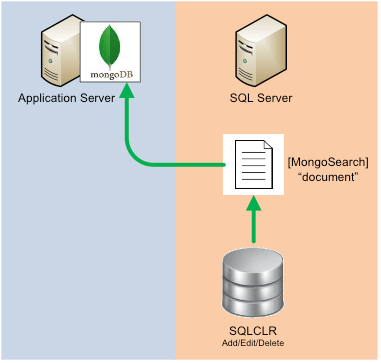
Step 4: Replicate the search functionality
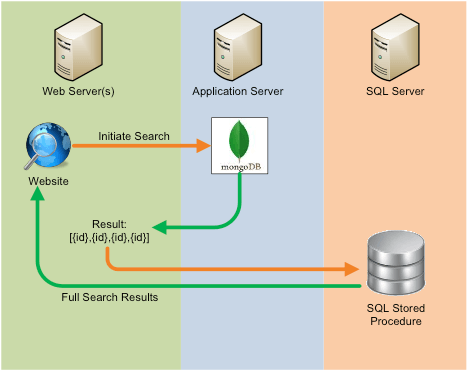
Since the data that we were storing in MongoDB was not a good representation of the actual SQL data, our solution went like this: - Call MongoDB with all search parameters and retrieve a list of the "main table" IDs as a result. - Pass the resulting list of IDs into a new SQL Search stored procedure in order to get the actual display data for the website’s search results data grids.
MongoDB provides several .Net dlls and sample code to get started building a query. You set a connection string for your MongoDB instance, then you build a query with all of your parameters and then you call a "find" passing in your parameters. The query parameters can be "equal to", "greater than", "less than", etc. I encourage you to explore more about MongoDB and NoRM if you want to know more specifics and limitations.
Results
We ran our tests from a developer laptop hosting the MVC website. We used a simple querystring parameter to use the "original” search routine or the new MongoDB routine. The MVC site used the same SQL Server 2008 R2 server in both cases.
Our first test was the search with no parameters chosen on the search form. In this case, the only filters are from the specific user logged in. Using the original search routine, this would normally return results (approximately 1000 matches) in close to 30 seconds and occasionally would time out. We ran the same test using MongoDB and the same exact set of results would be returned in under 2 seconds. A majority (>75%) of that time was spent in the initial query to get the "user specific” parameters and the final step to query SQL for the actual display data with the passed in the parameter of [IDs]. The step that actually searched MongoDB "documents” took less than half a second.
We then ran a series of searches with all kinds of combinations of search parameters in order to test the various flattened out data and the keyword search data. In every test, the MongoDB option was more than 10 times faster and the true "MongoDB” search step took almost no time at all. We compared resulting sets of data and presented our findings to the client.
We then worked with the client to move towards a production implementation of this solution with MongoDB installed on Amazon.com cloud servers and having MongoDB "sharded” across multiple servers. The resulting search functionality was vastly improved. I hope that this success story can help someone else to develop a great solution to a recurring problem using NoSQL.
Do you need an expert in web development? With a team of web development specialists covering a wide range of skill sets and backgrounds, The BHW Group is prepared to help your company make the transformations needed to remain competitive in today’s high-tech marketplace.